
강화학습
일반화된 정책 반복 (Generalized Policy Iteration)
정책 반복 알고리즘은 에피소드를 처음부터 끝까지 진행해 보고,
정책을 평가한 뒤 정책을 향상 시키는 방법이었다.
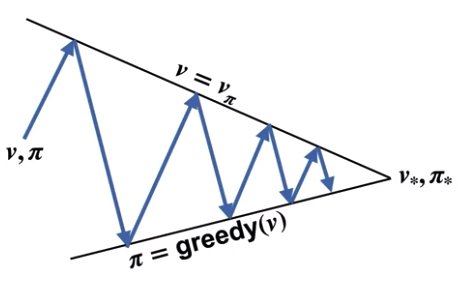
하지만 정책 반복은 이것보다 더 유연한 알고리즘이다.
정책 반복에서 끝까지 다 수했했던 것을 조금 줄여서,
아래의 그림과 같이 개선을 시킬 수도 있다.
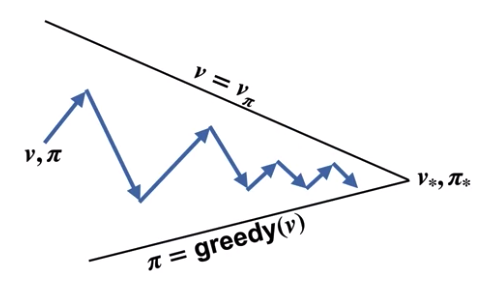
각각의 반복은 가치를 끝까지 향상시키지는 않고 조금씩 향상시킨다.
또한 각각의 개선은 정책을 최대의 탐욕으로 만들지 않고 조금씩 탐욕적으로 만든다.
이는 최종적으로는 최적 가치와 최적 정책에 도달하게 된다.
이 이론을 일반화된 정책 반복 (Generalized Policy Iteration)이라고 한다.
가치 반복 (Value Iteration)
가치 반복은 일반화된 정책 반복의 한가지의 적용법이다.
이 기법은 정책을 따라 모두 행동해보고 정책을 갱신하는 대신,
각 상태에 대해서 최대의 가치를 주는 행동으로 선택하고,
모든 상태를 경험한 뒤 정책을 갱신하는 방법이다.
이를 정리해놓은 알고리즘은 다음과 같다:

정책 반복을 해결하는 기법
다이나믹 프로그래밍은 정책반복을 푸는데 한가지 효율적인 방법으로 소개되었다.
아래는 이를 해결하는 몇가지 방법들을 더 설명한다.
몬테카를로 샘플링 (Monte-Carlo Sampling)
몬테카를로 기법, 혹은 몬테카를로 샘플링이란 가능한 많은 샘플을 모아 평균을 내는 기법이다.

이를 계속 반복하면 결국 몬테카를로 샘플링은 가치함수를 근사하게 된다.
하지만 이는 랜덤 샘플링을 반복하여 결과값 $G_t$를 산정하게 되는데,
이 떄 각 상태마다 가치를 산정하기 위한 많은 샘플링이 필요하기 때문에 시간이 오래걸리고 비효율적이다.
브루트 포스 검색 (Brute-Force Search)
부루트포스란 가능한 모든 경우의 수를 실행해보는 것을 의미한다.
적은 가지의 경우의수를 고려하더라도 이는 지수적으로 증가하기 떄문에,
매우 비효율적인 기법이 된다.
'데이터사이언스 > 강화학습' 카테고리의 다른 글
| 강화학습 - (15) 입실론 그리디 (0) | 2020.10.04 |
|---|---|
| 강화학습 - (14) 몬테카를로 (0) | 2020.10.04 |
| 강화학습 - (12) 정책 반복 (0) | 2020.09.28 |
| 강화학습 - (11) 정책 평가 (0) | 2020.09.28 |
| 강화학습 - (10) 벨만 최적 방정식 (0) | 2020.09.17 |