
강화학습
K-armed bandit의 한계
k-armed bandit 혹은 MAB 문제에서는 각 밴딧이 주는 확률과 보상이 같았다.
하지만 현실의 문제에서는 항상 그렇지 않다.
서로 다른 상황에서 같은 행동을 취하더라도 같은 보상을 얻을수는 없다.
또한 현재 취하는 행동이 추후에 받을 보상에 영향을 줄 수도 있다.
마르코프 결정과정은 이러한 두가지의 관점을 반영하고자 고안된 모델이다.
예제 1)

토끼 한마리가 왼쪽의 브로콜리와 오른쪽의 당근을 두고 고민하고 있다.
당근은 10의 보상을, 브로콜리는 3의 보상을 준다고 하면, 토끼는 당근을 선택할것이다.
그리고 같은 토끼에게 반대의 상황, 즉 당근과 브로콜리의 위치를 바꿔준다면,
토끼는 다시한번 당근을 선택할것이다.
k-armed bandit 문제는 이러한 상황을 고려하지는 않는다.
예제 2)
또 다른 예제를 살펴보자.

만약 위와 같이 당근 옆에 호랑이가 기다리고 있다면,
토끼는 절대 당근을 선택하지 않을 것이다.
당근을 먹는다면 다음에 올 상황이 어떤지 알고 있기 떄문이다.
따라서 장기적인 상황을 고려했을 때, 위와같은 상황에선 브로콜리를 선택할 것이다.
위 상황의 프로세스를 구성도로 그려보면 다음과 같다:
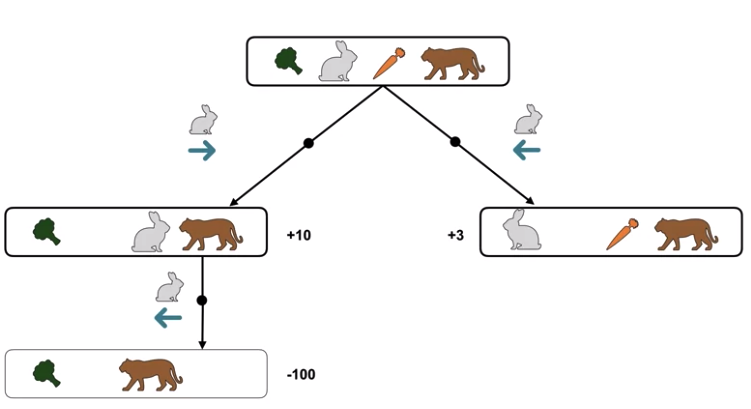
먼저 토끼가 오른쪽으로 움직여 당근을 먹는다면 당장은 10의 보상을 받지만,
바로 직후 호랑이에게 먹혀 -100의 보상을 잃게 된다.
반대로 왼쪽으로 움직인다면 3의 보상을 받고,
호랑이에게 먹히지 않아 보상을 잃지 않게 된다.
따라서 위 상황에서는 브로콜리를 먹는것이 장기적으로 최적의 행동이 된다.
마르코프 결정과정 (Markov Decision Process)
이러한 현실의 문제를 형식화한것이 마르코프 결정과정이다.
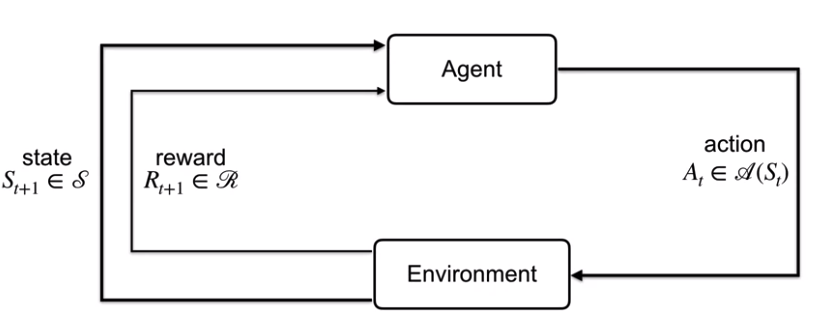
이 모델에서 에이전트(agent)와 환경(environment)은 서로 상호작용(interact)한다.
먼저 에이전트에게는 환경으로부터 상태(state, $S_t \in \mathbb{S}$)를 받고,
에이전트는 이 상태와 경험에 기반에 행동(action, $A_t \in \mathbb{S_t}$)을 선택한다.
에이전트가 선택한 행동을 기반으로, 환경은 새로운 상태($S_{t+1} \in \mathbb{S}$)를 주고,
또한 이 행동을 기반으로 보상(reward, $R_{t+1} \in \mathbb{R})을 준다.
에이전트가 현재 상태에서 다음 상태로 가는 것을 상태전환이라고 부르고,
이것을 확률론에 기반해 표현하여 상태전환확률(state transition probability, $p(s', r | s, a)$)라고 부른다.
상태전환확률은 확률이기 때문에 모든 확률을 더하면 1이 된다:
$$\sum_{s' \in \mathbb{S}}\sum_{r \in \mathbb{R}} p(s', r|s,a) = 1, \;\; \forall s \in \mathbb{S}, \forall a \in \mathbb{A}(s)$$
궤적 (Trajectory)
이러한 과정을 반복하면 에이전트와 환경은 궤적(Trajectory)을 만들게 된다.
이 궤적은 상태, 행동, 보상의 튜플(tuple, $<S, A, R>$)이다.
(많은 논문에서는 이 궤적을 그냥 상태와 행동의 튜플 $<S, A>$로 표현하기도 한다.)

이 궤적에서 어떠한 상태는 이전의 모든 상태에 대한 정보를 포함한다고 가정하는데,
이를 마르코프 속성(markov property)이라고 부른다.
이 마르코프 속성에 의해 MDP에서 모든상태는 다음상태를 예측할 수 있는 상태가 된다.
'데이터사이언스 > 강화학습' 카테고리의 다른 글
| 강화학습 - (7) 연속적인 결정과정 (0) | 2020.09.14 |
|---|---|
| 강화학습 - (6) 보상 (2) | 2020.09.07 |
| 강화학습 - (4) UCB (0) | 2020.08.27 |
| 강화학습 - (3) 탐색과 활용 (0) | 2020.08.24 |
| 강화학습 - (2) 행동가치함수 (2) | 2020.08.24 |