
강화학습
탐색과 활용
에이전트는 종종 탐색을 하기 위해서 최적이 아닌 행동들을 취해야 한다.
하지만 이는 꼭 필요하지 않은 작업일 수도 있다.
입실론 소프트 정책은 모든 행동에 대해 특정 확률을 부여함으로서,
행동하는 것과 학습하는것 모두 차선의(sub-optimal) 선택을 취했다.
오프 폴리시 (On-Policy)
지금까지 다루었던 모든 문제는 On-Policy 학습 방법에 해당했다.
On-Policy란 정책을 평가하고 향상하여 행동을 선택하는 학습 방법이다.
따라서 행동하는 정책과 학습하는 정책이 같다
온 폴리시 (Off-Policy)
반대로 Off-Policy란 행동하는 정책과 학습하는 정책이 다른 학습 방법이다.
이를 다른말로 표현하면, 행동을 선택하는 정책과 학습하는 정책이 각각 다르다는 의미이다.
Off-Policy 학습에서 타깃 정책(Target Policy)이란 우리가 결과적으로 학습하고자 하는 정책이다.
이 타깃 정책은 보통 $\pi(a|s)$로 표현되고, 이는 가치함수를 학습하는데 사용된다.
반대로 실제로 행동하는 정책을 행동 정책 (Behavior Policy) 라고 부른다.
이 행동 정책은 보통 $b(a|s)$로 표현되고, 이는 행동을 선택하는데 사용된다.
그렇다면 우리는 왜 타깃 정책과 행동 정책을 나누어 사용할까?
이렇게 하는 이유는 연속적인 탐색을 위해서이다.
만약 에이전트가 타깃 정책만을 활용한다면, 에이전트는 최종적으로 적은양의 상태만을 경험하게 된다.
반대로 에이전트가 탐색을 선호하는 정책을 활용한다면, 에이전트는 많은양의 상태들을 경험할 수 있다.
Off-Policy 학습 방법의 한가지 중요한 법칙은,
행동 정책이 타깃 정책을 포함하고 있어야 한다는 것이다.
$\pi(a|s) > 0$ 라면 $b(a|s) > 0$ 역시 만족해야 한다.
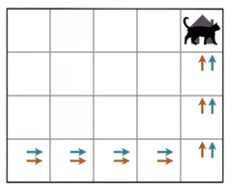
만약 위 그림에서 처럼 초기 상태에서 행동 정책이 항상 위로 가기를 원하고,
타깃 정책이 항상 오른쪽으로 가기를 원한다면, 에이전트는 절대 학습할 수 없다.
On-Policy와 Off-Policy의 관계
Off-Policy 학습 방법은 On-Policy 학습 방법의 상위 집합이라고 표현할 수 있다.
On-Policy는 Off-Policy의 특별한 케이스로,
행동 정책과 타깃 정책이 같은 학습 방법을 의미한다고 말할 수 있기 때문이다.
'데이터사이언스 > 강화학습' 카테고리의 다른 글
| 강화학습 - (18) 시간차 학습 (0) | 2020.10.04 |
|---|---|
| 강화학습 - (17) 중요도 샘플링 (0) | 2020.10.04 |
| 강화학습 - (15) 입실론 그리디 (0) | 2020.10.04 |
| 강화학습 - (14) 몬테카를로 (0) | 2020.10.04 |
| 강화학습 - (13) 가치 반복 (0) | 2020.10.03 |