
강화학습
정책 근사
정책 학습
정책은 에이전트가 어떻게 행동하는지를 정의한다.
TD기반 기법들이 행동가치를 예측하는 것은 간단한 확률 기반의 입실론 그리디를 사용했기 때문이다.
하지만 행동가치를 예측하기 전에, 정책 또한 함수로서 근사가 가능하다.
정책을 함수로서 표현한다면, 상태의 표현을 받아 행동을 할 확률을 내는것이라 말할 수 있다.
예제)
강화학습에서 유명한 게임중 하나인 Mountin Car라는 게임을 예로 들어본다.
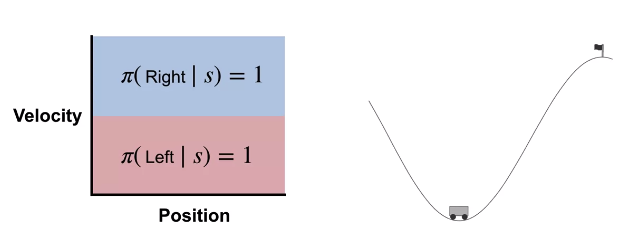
자동차가 언덕 위의 깃발에 도달해야한다고 할 떄,
위와 같은 두가지의 행동을 하는 정책을 정의할 수 있다.
정책 함수 근사
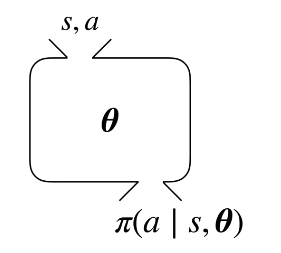
정책 함수를 근사하는 파라미터는 위와 같이 $\theta$로 표현한다.
위 함수는 모든 상태에 대해 모든 행동들에 대한 확률을 반환해야 한다.
따라서 모든 행동에 대해 정책함수가 반환하는 확률의 값은 0과 같거나 커야한다:
$\pi(a | s, \theta) >= 0, \; \forall a \in A, \forall s \in S$
또한 정책 함수가 반환할 값은 확률이기 때문에, 모든 행동들을 취할 확률을 더하면 1이 되어야 한다:
$\pi_{a \in A} \pi(a | s, \theta) = 1, \; \forall s \in S$
이러한 속성 때문에 정책 함수 근사에는 선형 함수 근사가 사용될 수 없다.
일반적으로 선형 함수 근사는 전부 더해서 1이 될수 없기 때문이다.
소프트맥스 정책 (Softmax Policy)
모든 행동을 확률로 만들기 위한 가장 간단한 방법은 소프트맥스 함수를 정책으로 사용하는 것이다:
$\pi(a|s,\theta) \dot{=} \frac{e^{h(s,a,\theta)}}{\sum_{b \in A} e^{h(s,b,\theta)}}$
위 수식에서 $h(s, a, \theta)$는 행동 선호도이다.
각 행동에 대한 선호도를 지수화 하고, 모든 행동에 대한 선호도를 지수화해서 더한 것으로 나누면,
이는 0~1 사이의 값이 나오게 된다.
지수함수는 각 행동선호도가 0이 아닌 값이 되게 만들어주고,
이 행동선호도는 선형근사기나 인공신경망과 같은 함수 근사기를 통해 근사할 수 있다.
예제)
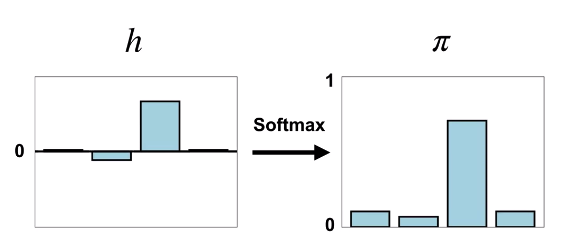
행동선호도 $h$를 소프트맥스를 통해 확률로 바꾼 결과이다.
3번째 행동의 선호도와 같이 아주 큰 값들은 1에 가까워지지만, 절대 1을 넘어갈 수는 없다.
또한 마이너스의 값의 선호도를 가지고 있더라도, 0 이상의 확률을 갖게 된다.
행동선호도 vs 행동가치
여기서 주의할 점이 하나 있는데, 행동선호도는 행동가치가 아니라는 점이다.
먼저 행동가치는 절대적인 값이다: 행동가치는 보상을 통해 산정되는 가치값이다.
모든 행동가치에 100을 다 더하는 것은 행동들의 상대적인 가치를 변하게 한다.
하지만 행동선호도는 상대적인 값이다.
따라서 모든 행동선호도에 100을 더한다고 해도 행동선호도의 비율은 변하지 않는다.
예제)
다음은 소프트맥스와 입실론그리디를 비교한 것이다:
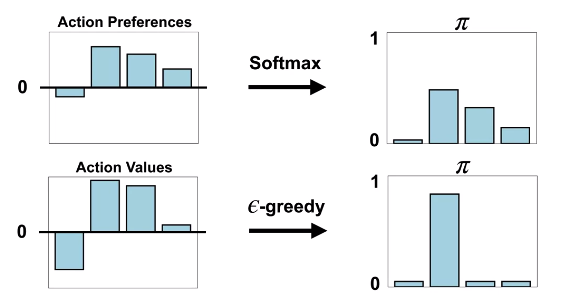
입실론 그리디에서는 가장 가치가 큰 행동을 가장 선호하고, 다른 행동들을 비슷하게 선호하게 된다.
이는 랜덤과 탐욕적인 성향을 모두 가진 정책이기 때문이다.
하지만 소프트맥스 정책은 그렇지 않다.
소프트맥스 정책은 각 행동들의 선호도에 따라 확률을 분배하게 된다.
정책 근사의 장점
정책 근사는 탐색과 활용을 학습과정에서 자발적(autonomous)으로 할 수 있다.
입실론 그리디를 생각해보면, 우리가 언제 탐색을 끝내고 활용을 할지를 정해주어야 한다.
하지만 정책을 근사하면, 초반에 에이전트가 학습이 잘 안되었을 때는 자연적으로 탐색하게 되고,
학습이 어느정도 진행 될 수록 점점 더 탐욕적(greedy)으로 바뀌게 된다.
소프트맥스 정책이 잘 학습 된다면, 가장 좋은 행동을 선택하게 된다는 것과 같다.
또한 행동 공간이 너무 크지 않은 문제를 풀고있다면,
정책 근사를 하는 것이 더 효율적인 문제가 더 많을 것이다.
이러한 상황에서는 확률적 정책으로 정책 학습을 하는것이,
가치함수를 학습하는것 보다 훨씬 빠르게 문제를 풀어낼 수 있다.
'데이터사이언스 > 강화학습' 카테고리의 다른 글
| 강화학습 - (26-1) REINFORCE 코드예제 (0) | 2020.12.21 |
|---|---|
| 강화학습 - (26) 정책 경사 (0) | 2020.12.16 |
| 강화학습 - (24-1) Deep SARSA 코드예제 (0) | 2020.12.07 |
| 강화학습 - (24) 시간차 가치 근사 (0) | 2020.11.21 |
| 강화학습 - (23) 몬테카를로 가치 근사 (0) | 2020.11.17 |