맵리듀스 복습
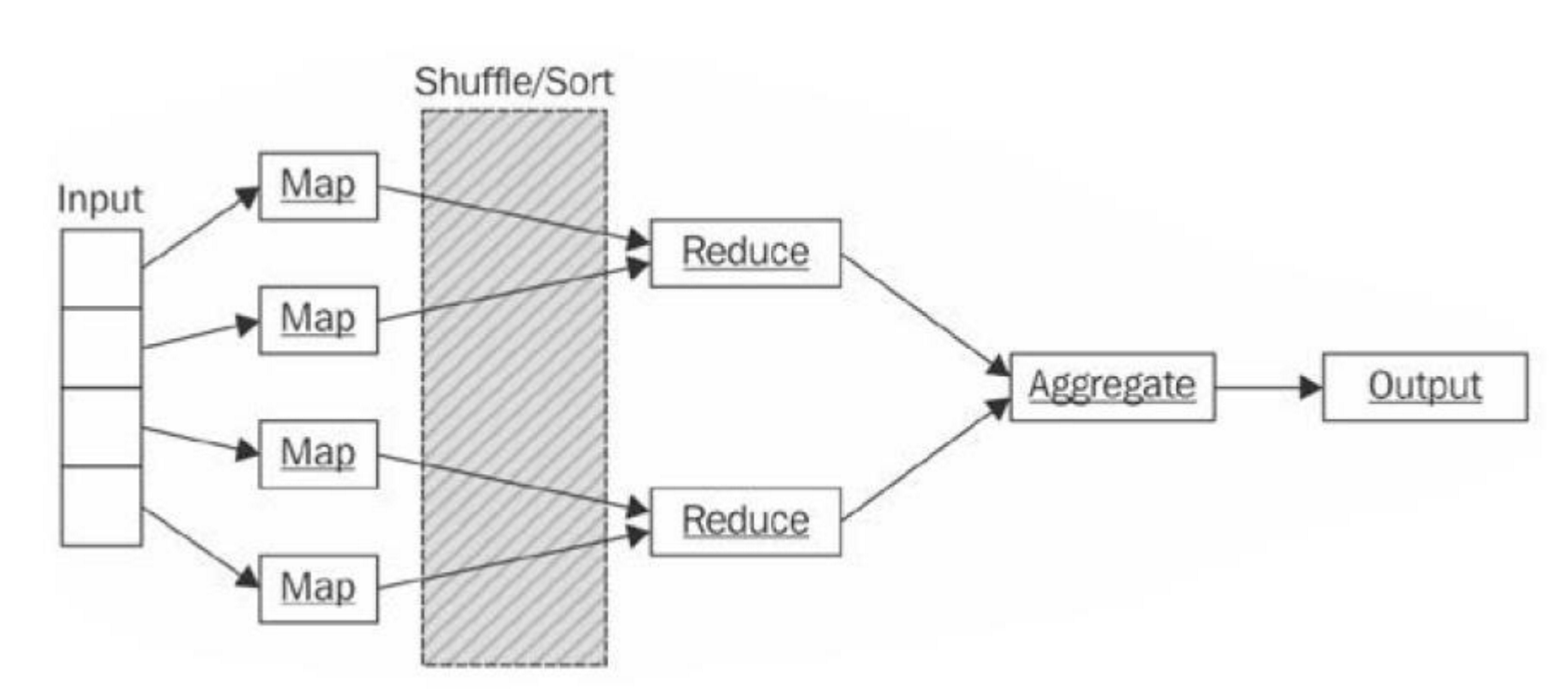
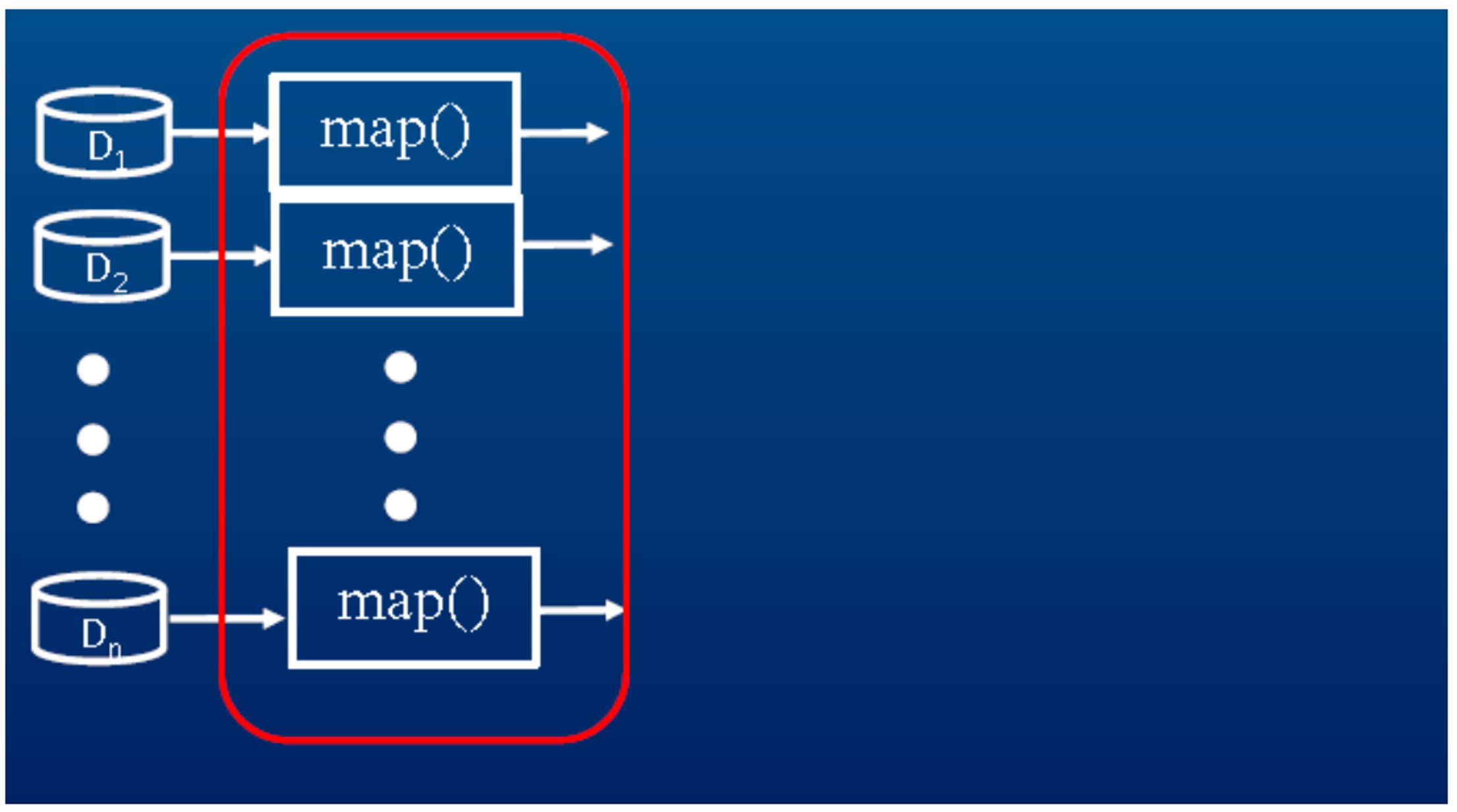
맵 단계
- 위 그림에서는 맵을 수행할 수 있는 기기가 4개 있음
- 인풋 단계의 데이터를 4개의 블록으로 나누고, Map이라는 Task를 각 기기에 분배해 준다.
- Map을 수행하는 TaskTracker는 해당 작업을 수행하게 된다.
- Map을 실제로 짜는것은 개발자의 몫이다
- Input을 받아 Output을 내는 각각의 함수를 작성한다.
- <key, value>쌍으로 입력을 받고 로컬에 파일로 저장한다.

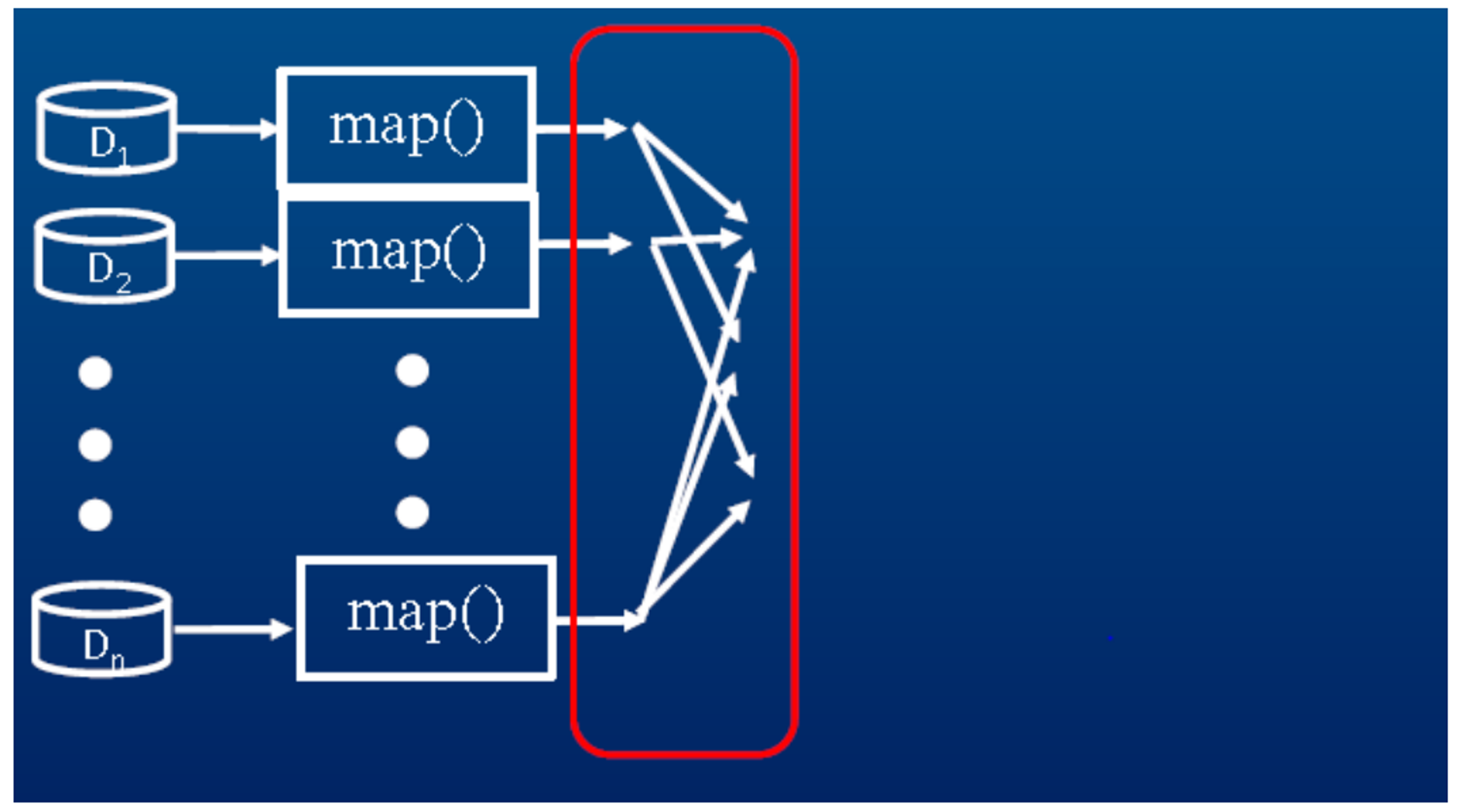
셔플 단계
- 위 함수의 결과를 받아 하둡 시스템이 셔플을 진행한다.
- 정렬된 리스트를 다시 리듀스 TaskTracker기기에 전달한다.
- 셔플은 시스템이 알아서 수행해 준다.
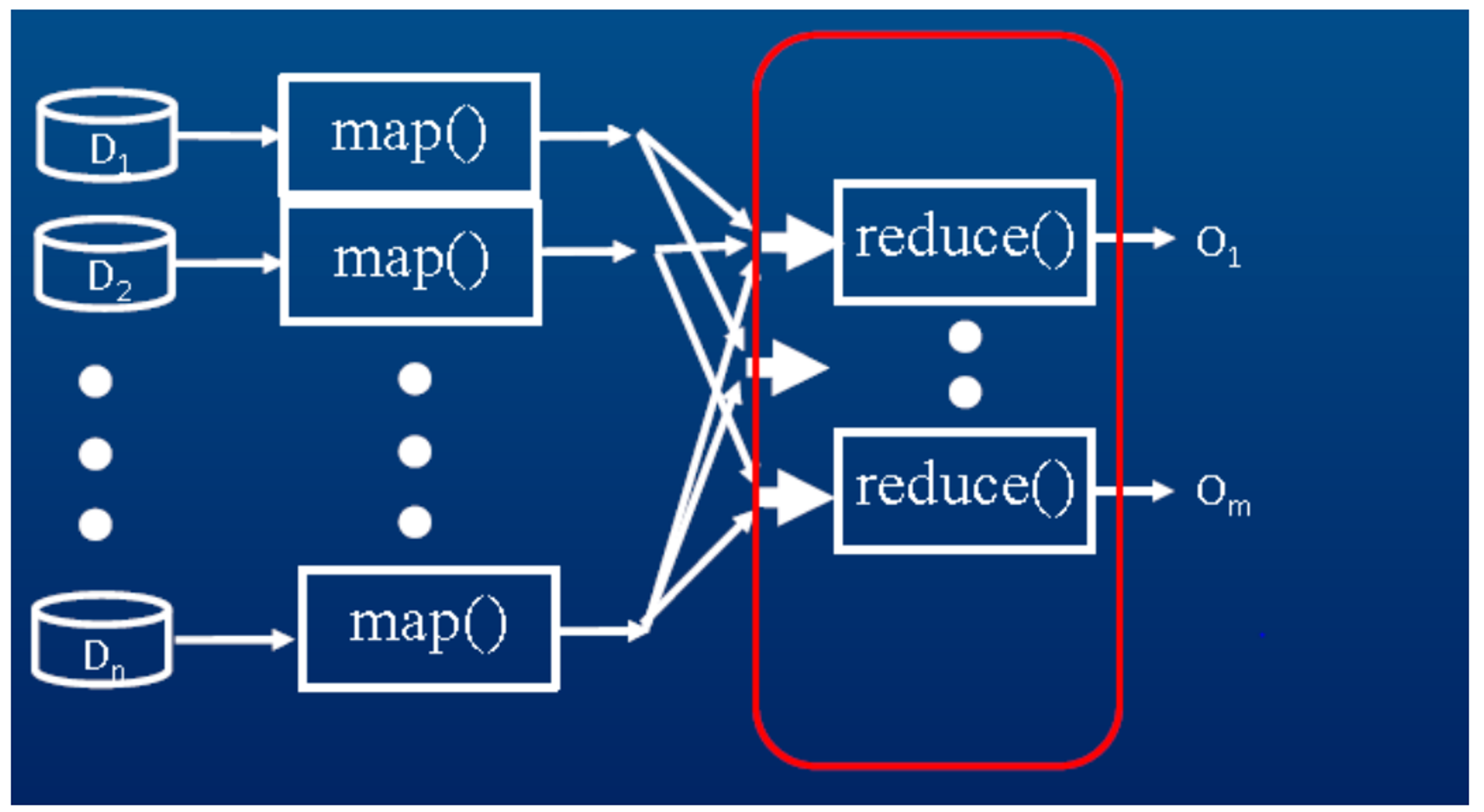
리듀스 단계
- 리듀스 함수는 집계를 하고, 얻어진 결과를 파일로 출력하는 일을 수행한다.
- 리듀스도 TaskTracker가 수행하는데, 함수는 역시 개발자가 정의를 한다.
- 리듀스함수 역시 Input과 Output함수가 각각 정의가 되어있다.
- 마지막 결과는 hdfs에 파일로 떨구게 된다.

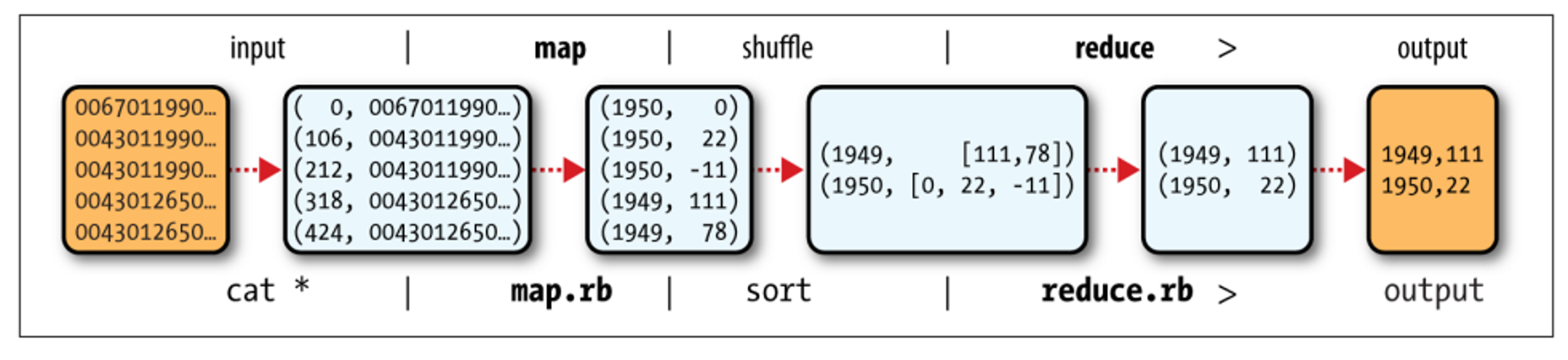
하둡완벽가이드 예제 (pg 19 - 29)
데이터의 지역성
하둡 파일시스템의 한 블록은 128MB로 한다. (파일은 더 크다고 가정)
만약 파일이 너무 작다면 (128MB보다 작은 사이즈) 많이 들어온다면, 하둡에게 그렇게 좋지 않은 파일을 넣는것이다. --> 성능이 좋아지지 않는다.
각 파일시스템은 디스크를 가지고 있다. 그 디스크에서 실제로 가지고 있는 파일에 대한 계산을 하는게 성능이 더 좋다. 네트워크를 거치지 않기 때문이다. 이를 데이터의 지역성 (Data Locality)이라고 한다. 따라서 하둡은 네트워크 사이에서 계산이 왔다갔다 하는것을 최대한 막는것으로 최적화를 한다.
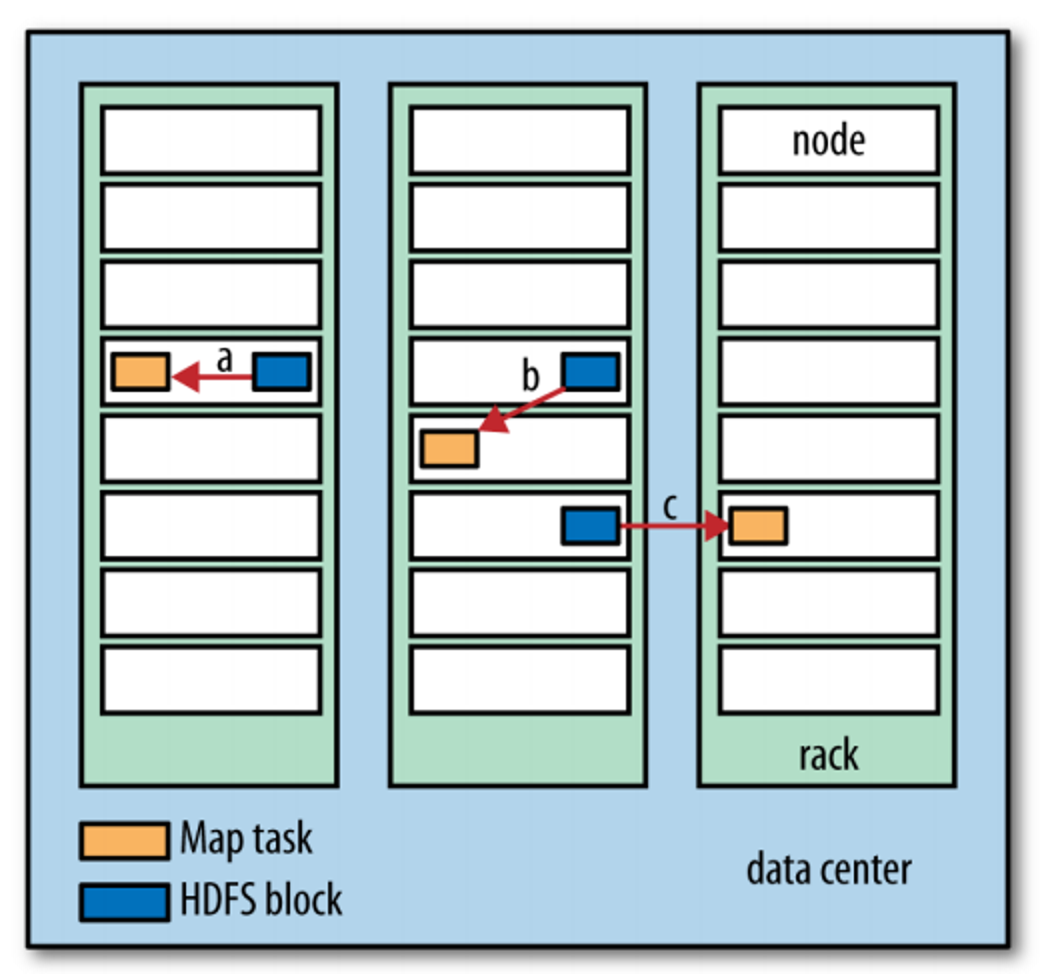
위의 그림에서 a는 node 자신, 기기 자신에 있는 데이터를 접근하는 것이다. 이게 가장 빠르다
b는 같은 rack에 있는 다른 기기의 데이터를 접근한다. 자신의 데이터보다는 느리지만 다른 rack에 있는 데이터를 접근하는 c보다는 빠르다.
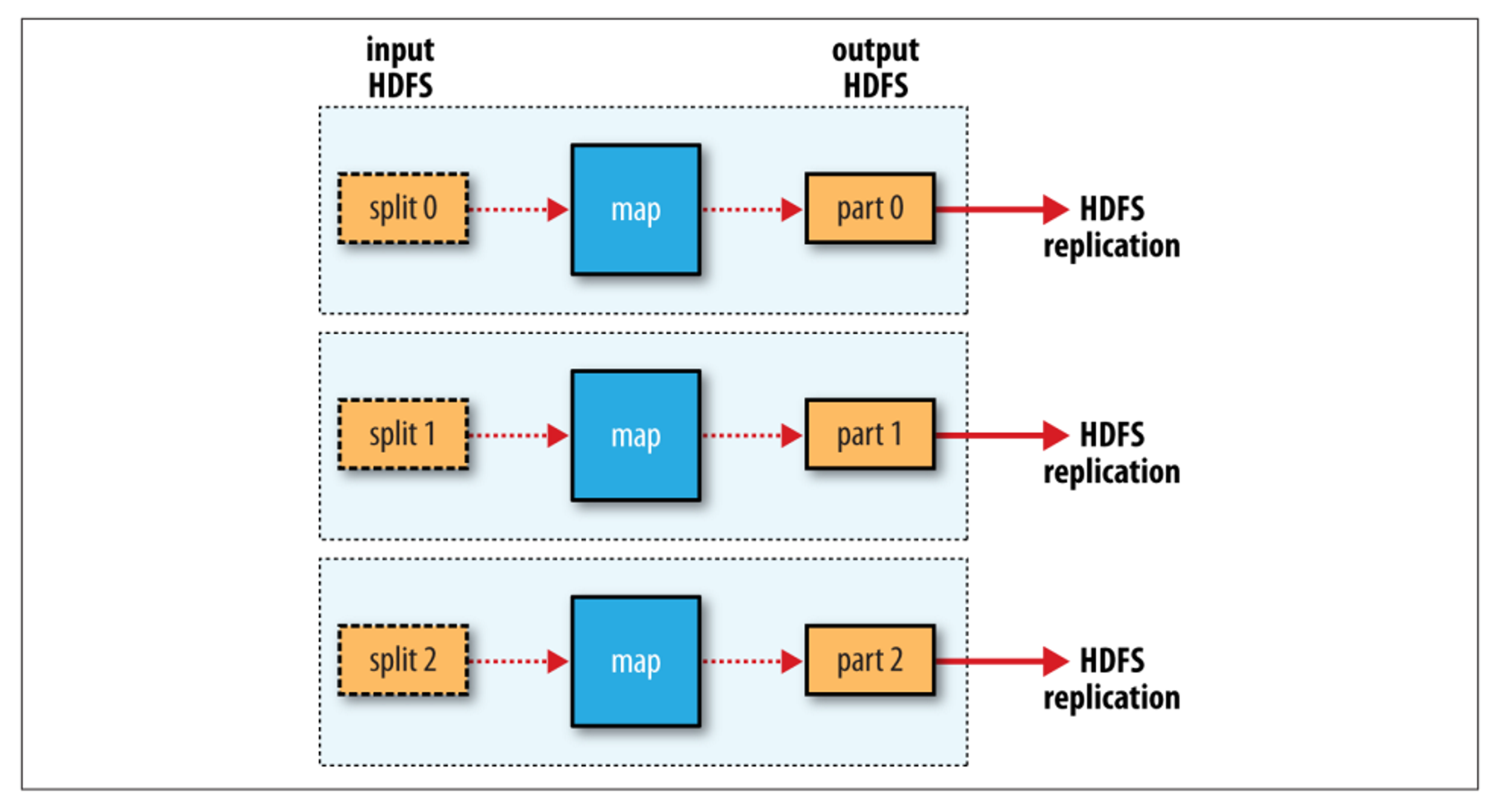
맵리듀스의 기본적인 태스크 구성도는 다음과 같다. 하나의 리듀스 잡을 수행하는 그림이다.
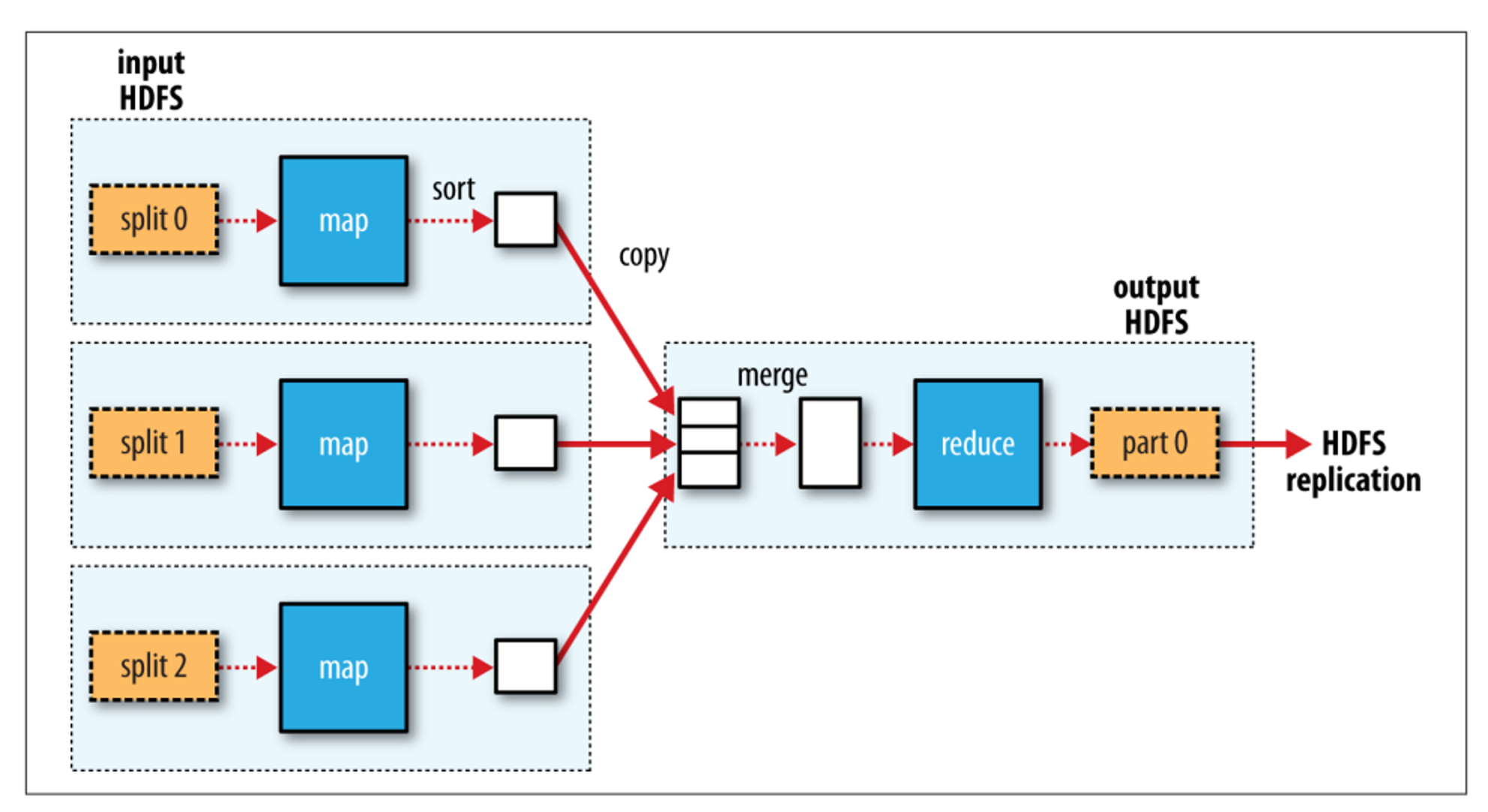
먼저 각 워커에서 맵태스크를 실행할 때는 자신의 로컬 디스크에 맵의 결과를 저장한다. 그리고 리듀스태스크가 끝나면 하둡의 파일시스템에 Replication, 즉 복제가 된다.
다음은 두개의 리듀스잡을 수행하는 그림이다.
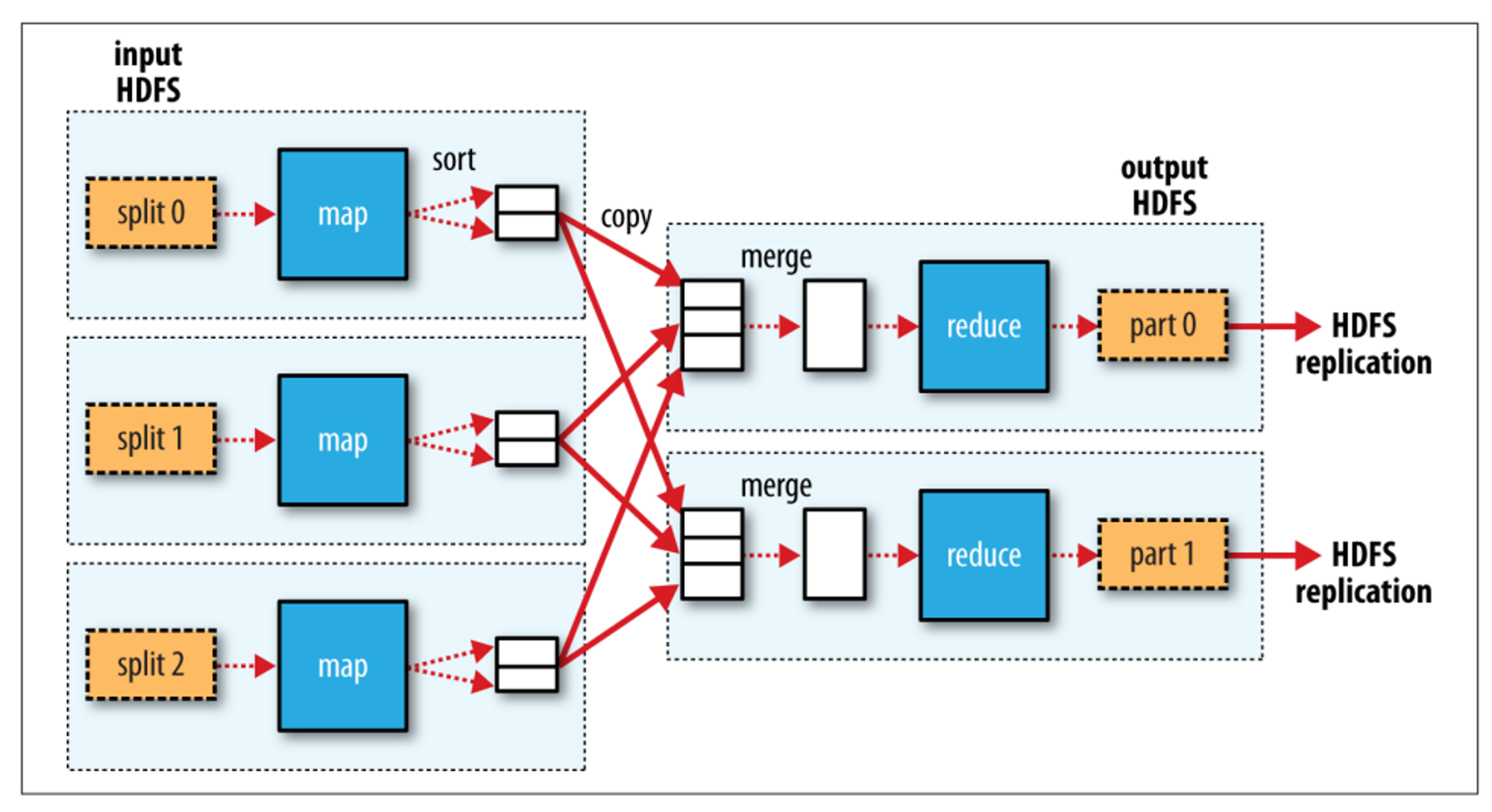
만약 맵태스크에서 파티션이 생긴다면, 두개의 리듀스태스크가 생성되어야 한다. 이처럼 파티션이 생기는 경우는 셔플링과 소팅이 일어나게 되는데 이런 경우에 데이터의 지역성이 중요해지는 것이다.
마지막으로 리듀스태스크가 없는 경우도 있다.
이런 경우는 특수한 경우이다. 데이터를 Split하지 않고 처리해야하는 잡은 굳이 리듀스태스크를 실행하지 않는것이 효율적일 것이다.
성능 개선이 필요한 경우에는, 맵태스크가 끝내는 부분에 전송을 최소화 하기 위해서 Combiner를 둘 수도 있다. Combiner에서는 너무 많은 맵의 태스크가 그대로 네트워크를 통해 리듀서로 전달되는 상황에서 Bottleneck을 줄이기 위해 리듀서의 짐을 덜어주기 위함이다. 하지만 Combiner는 모든 상황에서 사용할 수 있는것은 아니니 상황에 맞춰 사용해야 한다.
하둡 스트리밍
하둡은 파이썬이나 루비를 사용해서 스트리밍 형태의 데이터를 맵리듀스로 처리할 수 있다.