
데이터 준비
데이터 설명
이번에는 맵리듀스를 사용해 실제 데이터 분석을 해보려 합니다.
먼저 다음 사이트에서 데이터를 다운받아야 합니다.
http://stat-computing.org/dataexpo/2009/the-data.html
위의 링크의 데이터는 미국 내 모든 항공편에 대한 도착과 출발에 대한 세부 정보들을 담은 데이터입니다.
년, 월, 등 시간 및 항공사 정보, 출발시간, 도착시간, 출발지, 도착지 등에 대한 데이터가 들어있습니다.
데이터 다운로드
위의 링크로 들어가면 년도별로 데이터를 다운받을 수 있지만,
Shell Script를 사용해 한번에 데이터를 내려받고, 수정하도록 하겠습니다.
수정 내용은, 첫줄의 컬럼정보를 없애는 작업입니다.
#!/bin/bash
for ((i=1987; i <= 2008; i++)) ; do
wget http://stat-computing.org/dataexpo/2009/$i.csv.bz2
bzip2 -d $i.csv.bz2
sed -e '1d' $i.csv > $i_temp.csv
mv $i_temp.csv $i.csv
done위의 Shell Script는 어떠한 OS에서 사용하느냐에 따라 동작하지 않을 수 있습니다. (Ubunut기준입니다.)
CentOS는 첫줄을 #! /bin/bash로 고치시면 되고,
윈도우가 호스트이고 Python 3.x가 깔려있다면 다음 코드를 사용하시면 될것같습니다.
import urllib.request as request
import bz2
import os
for i in range(1987, 2009):
url = "http://stat-computing.org/dataexpo/2009/{}.csv.bz2".format(i)
out_fname = "./{}.csv.bz2".format(i)
final_fname = "./{}.csv".format(i)
request.urlretrieve(url, out_fname)
print("downloaded file: {}".format(out_fname))
with bz2.open(out_fname, "rb") as in_file, open(final_fname, "w") as out_file:
data = in_file.read().decode('utf-8').split('\n')[1:]
data = "\n".join(data)
out_file.write(data)
print("wrote file: {}".format(final_fname))
for item in os.listdir('./'):
if item.endswith('.bz2'):
os.remove(os.path.join('./', item))
다운로드를 받으신 뒤 다음 리눅스 명령어를 입력하시면 해당 폴더가 차지하는 데이터 양을 볼 수 있습니다.
> du -s -h .데이터는 약 12G정도 되는 것 같습니다.
(혹시라도 각 VM의 사이즈를 20기가 밑으로 잡으신 분들은 하둡으로 업로드가 힘드실테니 각각 업로드 후 하둡에 집어넣으셔야 할 것 같습니다.)
파일 옮기기
이제 scp를 이용해 doop01로 파일을 옮겨주겠습니다.
> scp -rp . doop@doop01:~/
그리고 하둡파일시스템으로 csv파일을 넣어줍니다.
VM의 용량을 20기가 이상으로 잡으셨다면 상관 없겠지만,
혹시 모를 염려가 생겨 하나씩 hdfs에 복사하고 namenode 기기 즉 doop01의 로컬에 있는 파일을 지우는 Shell Script를 작성했습니다.
#!/bin/sh
./hadoop/bin/hadoop dfs -mkdir input
for ((i=1987; i <= 2008; i++)) ; do
./hadoop/bin/hadoop dfs -put ~/$i.csv input
rm -rf $i.csv
done
혹시라도 신경을 안쓰시거나 각 VM을 20기가 이상 잡으셨다면 다음 커맨드를 사용하시기 바랍니다.
> hadoop dfs -mkdir input
> hadoop dfs -put ~/doop/*.csv input참고로 dfs는 fs와 동일한 기능을 합니다.
전송 결과 확인
파일을 HDFS로 옮기는 것이 끝났다면 마지막으로 확인을 해주겠습니다.
> hadoop dfs -ls다음과 같은 로그가 나올 것입니다.
Found 22 items
-rw-r--r-- 3 doop supergroup 127162642 2019-07-14 11:05 /user/doop/input/1987.csv
-rw-r--r-- 3 doop supergroup 501039172 2019-07-14 11:05 /user/doop/input/1988.csv
-rw-r--r-- 3 doop supergroup 486518521 2019-07-14 11:05 /user/doop/input/1989.csv
-rw-r--r-- 3 doop supergroup 509194387 2019-07-14 11:05 /user/doop/input/1990.csv
-rw-r--r-- 3 doop supergroup 491209793 2019-07-14 11:05 /user/doop/input/1991.csv
-rw-r--r-- 3 doop supergroup 492313431 2019-07-14 11:06 /user/doop/input/1992.csv
-rw-r--r-- 3 doop supergroup 490753352 2019-07-14 11:06 /user/doop/input/1993.csv
-rw-r--r-- 3 doop supergroup 501558365 2019-07-14 11:06 /user/doop/input/1994.csv
-rw-r--r-- 3 doop supergroup 530751268 2019-07-14 11:06 /user/doop/input/1995.csv
-rw-r--r-- 3 doop supergroup 533922063 2019-07-14 11:06 /user/doop/input/1996.csv
-rw-r--r-- 3 doop supergroup 540347561 2019-07-14 11:06 /user/doop/input/1997.csv
-rw-r--r-- 3 doop supergroup 538432575 2019-07-14 11:07 /user/doop/input/1998.csv
-rw-r--r-- 3 doop supergroup 552925722 2019-07-14 11:07 /user/doop/input/1999.csv
-rw-r--r-- 3 doop supergroup 570151313 2019-07-14 11:07 /user/doop/input/2000.csv
-rw-r--r-- 3 doop supergroup 600411162 2019-07-14 11:07 /user/doop/input/2001.csv
-rw-r--r-- 3 doop supergroup 530506713 2019-07-14 11:08 /user/doop/input/2002.csv
-rw-r--r-- 3 doop supergroup 626744942 2019-07-14 11:08 /user/doop/input/2003.csv
-rw-r--r-- 3 doop supergroup 669878813 2019-07-14 11:08 /user/doop/input/2004.csv
-rw-r--r-- 3 doop supergroup 671026965 2019-07-14 11:08 /user/doop/input/2005.csv
-rw-r--r-- 3 doop supergroup 672067796 2019-07-14 11:09 /user/doop/input/2006.csv
-rw-r--r-- 3 doop supergroup 702877893 2019-07-14 11:09 /user/doop/input/2007.csv
-rw-r--r-- 3 doop supergroup 689413044 2019-07-14 11:09 /user/doop/input/2008.csv
파일이 정확히 들어갔는지 내용을 보고싶다면, 파일을 하나 골라 마지막 내용을 출력해볼 수 있습니다.
> hadoop dfs -tail input/1988.csv결과는 다음과 같이 나옵니다.
1988,12,7,3,1325,1325,2057,2034,DL,162,NA,332,309,NA,23,0,HNL,LAX,2556,NA,NA,0,NA,0,NA,NA,NA,NA,NA
1988,12,8,4,1325,1325,2042,2034,DL,162,NA,317,309,NA,8,0,HNL,LAX,2556,NA,NA,0,NA,0,NA,NA,NA,NA,NA
1988,12,9,5,1325,1325,2055,2034,DL,162,NA,330,309,NA,21,0,HNL,LAX,2556,NA,NA,0,NA,0,NA,NA,NA,NA,NA
1988,12,10,6,1325,1325,2258,2034,DL,162,NA,453,309,NA,144,0,HNL,LAX,2556,NA,NA,0,NA,0,NA,NA,NA,NA,NA
1988,12,11,7,1325,1325,2051,2034,DL,162,NA,326,309,NA,17,0,HNL,LAX,2556,NA,NA,0,NA,0,NA,NA,NA,NA,NA
1988,12,12,1,1325,1325,2043,2034,DL,162,NA,318,309,NA,9,0,HNL,LAX,2556,NA,NA,0,NA,0,NA,NA,NA,NA,NA
1988,12,13,2,1325,1325,2038,2034,DL,162,NA,313,309,NA,4,0,HNL,LAX,2556,NA,NA,0,NA,0,NA,NA,NA,NA,NA
1988,12,14,3,1325,1325,2045,2034,DL,162,NA,320,309,NA,11,0,HNL,LAX,2556,NA,NA,0,NA,0,NA,NA,NA,NA,NA
1988,12,1,4,2027,2027,2152,2145,DL,163,NA,85,78,NA,7,0,ATL,MCO,403,NA,NA,0,NA,0,NA,NA,NA,NA,NA
1988,12,2,5,2106,2027,2229,2145,DL,163,NA,83,78,NA,44,39,ATL,MCO,403,NA,NA,0,NA,0,NA,NA,NA,NA,NA
프로젝트 생성
파일 복사가 끝났다면 이제 프로젝트를 생성해주겠습니다.
IntelliJ를 열어 새 프로젝트를 만들어줍니다. 이름은 airlinedata라고 짓겠습니다.
com > jyoon > study > airlinedata라는 패키지 구조를 만들어주겠습니다.
Gradle Dependency
이전 워드카운트 문제와 동일하게 dependency는 다음과같이 두개의 라이브러리를 사용하겠습니다.
dependencies {
testCompile group: 'junit', name: 'junit', version: '4.12'
implementation 'org.apache.hadoop:hadoop-common:3.1.2'
implementation 'org.apache.hadoop:hadoop-mapreduce-client-core:3.1.2'
}
Parser 클래스
가장 먼저 Parser클래스를 구현할 것입니다. 이 클래스는 위의 항공데이터 중 출발 지연시간과 도착 지연시간을 추출하기 위해 작성합니다. 코드를 작성하기 전에 위의 샘플 데이터의 가장 마지막 한줄의 정보를 테이블로 만들어보겠습니다.
| 컬럼 이름 | 운항년도 | 운항월 | 항공사코드 | 도착지연시간 | 출발지연시간 | 운항거리 |
| 컬럼 인덱스 | 0 | 1 | 8 | 14 | 15 | 18 |
| 정보 | 1988 | 12 | DL | 44 | 39 | 403 |
아래 코드는 Comma로 split한 뒤 위의 컬럼들만 뽑아내는 역할을 하는 코드입니다.
AirlinePerformanceparser.java라고 이름 짓고 다음 코드를 작성해줍니다.
import org.apache.hadoop.io.Text;
public class AirlinePerformanceParser {
private int year;
private int month;
private int arrivalDelayTime = 0;
private int departureDelayTime = 0;
private int distance = 0;
private boolean arrivalDelayAvailable = true;
private boolean departureDelayAvailable = true;
private boolean distanceAvailable = true;
private String uniqueCarrier;
public AirlinePerformanceParser(Text text){
try {
// 한 row를 comma로 split 한다
String[] columns = text.toString().split(",");
year = Integer.parseInt(columns[0]); // 운항 년도
month = Integer.parseInt(columns[1]); // 운항 월
uniqueCarrier = columns[8]; // 항공사 코드
if (!columns[15].equals("NA")) // 항공기 출발 지연 시간
departureDelayTime = Integer.parseInt(columns[15]);
else
departureDelayAvailable = false;
if (!columns[14].equals("NA")) // 항공기 도착 지연 시간
arrivalDelayTime = Integer.parseInt(columns[14]);
else
arrivalDelayAvailable = false;
if (!columns[18].equals("NA")) // 운항 거리
distance = Integer.parseInt(columns[18]);
else
distanceAvailable = false;
} catch (Exception ex){
System.out.println("Error parsing a record: " + ex.getMessage());
}
}
}
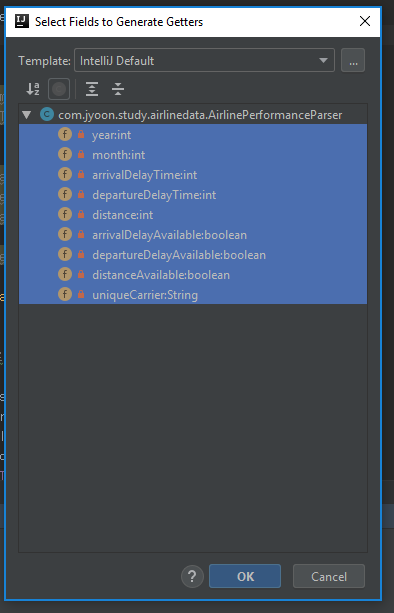
위 코드를 작성한 뒤 IntelliJ에서 member변수 중 하나에 오른쪽 클릭을 하고, Generate을 클릭해줍니다.

이후 뜨는 팝업 창에서 Getter를 선택하고,

모든 변수들을 다 선택해준 뒤 OK를 누르면 Getter함수들을 자동으로 생성하게 됩니다.
다음 포스팅에서는 맵리듀스로 해당 데이터를 조회하고 분석해보겠습니다.
참고자료
이 포스팅은 "시작하세요! 하둡 프로그래밍" 책의 예제를 무작정 따라해본 포스팅입니다.
'빅데이터 > 하둡' 카테고리의 다른 글
| 하둡 1.0 튜토리얼 - (11) 사용자 정의 옵션 (0) | 2019.07.17 |
|---|---|
| 하둡 1.0 튜토리얼 - (10) 항공 데이터 분석 2 (2) | 2019.07.15 |
| 하둡 1.0 튜토리얼 - (8) 맵리듀스 (0) | 2019.07.14 |
| 하둡 1.0 튜토리얼 - (7) HDFS 파일 입출력 (0) | 2019.07.14 |
| 하둡 1.0 튜토리얼 - (6) HDFS 명령어 (0) | 2019.07.12 |