
강화학습
불확실성과 결정과정 (Uncertainty & Decision Process)
강화학습에서는 Trial-and-error를 통해서 여러차례 반복을 통해 학습을 하는 경우가 많다.
보통의 기계학습과는 다르게 에이전트가 놓여진 환경에서 스스로 학습 데이터를 만들어내고 학습한다.
처음보는 불확실한 환경속에서 에이전트는 여러 차례 시도를 통해 학습하는데,
이러한 프로세스를 불확실성(uncertainty) 속의 결정과정(decision making process) 라고 한다.
K-armed bandit 문제

이러한 문제는 강화학습에서 종종 Bandit문제로 표현된다.
Bandit이란 슬롯머신의 손잡이를 일컷는 말로,
각 슬롯머신 손잡이를 선택했을 때 각 손잡이를 당겼을 때 얻는 보상이 다를때의 상황을 이야기한다.
이러한 문제를 Multi-armed Bandit 혹은 K-armed Bandit 문제라고 한다.
예제)

한 의사가 3가지의 약재를 사용하려고 한다.
환자가 올때 마다 랜덤으로 한가지 약재를 사용해 환자를 치료한다.
그 때마다 환자의 건강상의 반응을 보고 이 약재가 좋은 것인지를 판단하려 한다.
의사는 파란색 약재가 좋은 효과를 내는 것을 찾았다면,
이제 현재까지 가장 좋은 효과를 내는 이 약재를 계속 사용할 것인지,
아니면 다른 약재도 시도해볼 것인지를 결정해야 한다.
먄약 파란색 약재만을 사용한다면, 다른 약재들에 대한 데이터는 더이상 모으지 못하게 된다.
위 다른 두 약재들 중 하나가 사실은 더 좋은 약재이지만,
우연에 의해 어떠한 환자들에게 나쁜 효과를 냈을지는 더이상 알 수 없게 된다.
K-armed bandit 문제에서 에이전트(agent) 는 k개의 다른 행동(action)을 취하고,
취한 행동에 따른 보상(reward)를 받는다.
위의 예제에서 에이전트는 의사이고, 각각의 약재는 k=3인 행동이 된다.
그리고 보상은 환자의 건강에 좋은 반응을 보였는가가 될 것이다.
행동가치함수 (Action-Value Function)
행동가치함수는 한 행동이 어떠한 가치를 주는가를 판단한다.
이를 확률론에 기반에 정의하면 다음과 같이 정의할 수 있다:
$$q^*(a) \dot{=} \mathbb{E}[R_t | A_t = a] \;\; \forall a \in {1, ..., k}$$
이는 곧 한 행동을 취할 확률은 예상되는 보상값으로 정의할 수 있음을 의미한다.
위 수식에서 행동가치함수 $q*(a)$는 모든 행동 a에 대해서,
$A_t = a$가 주어졌을 때 예상되는(expected) $R_t$로 정의한다
위의 수식은 또한 다음과 같이 재정의 될 수 있다:
$$q^*(a) = \sum_r p(r|a)r$$
기대수식은 보상과 해당 보상을 얻을 수 있는 확률의 합으로 이루어져 있고,
만약 연속적인(continuous) 보상이 주어지는 상황이라면 $\sum$를 $\int$로 바꿔주면 된다.
이는 역시 에이전트의 최종적인 목표가 보상을 최대화 하는 것임을 의미 하는데,
강화학습에서는 주로 이를 다음과 같이 표현한다:
$$argmax_a q^*(a)$$
argmax는 함수의 결과값을 최대화 하는 인자값 a를 찾는것으로,
위의 경우에서는 보상을 최대화 하는 행동을 찾는것이 된다.
예제)
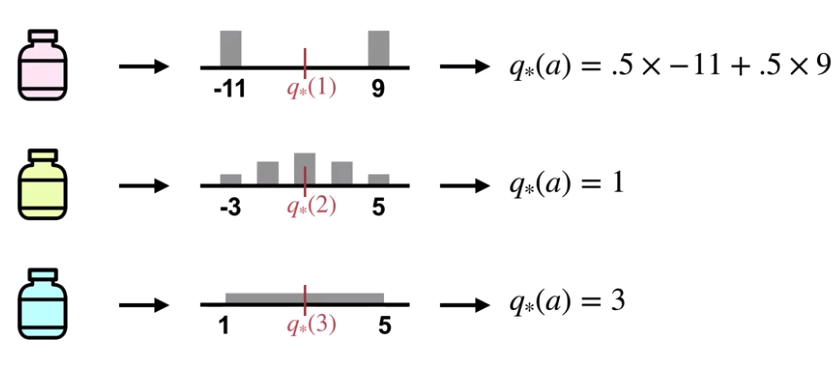
의사가 각 약재를 선택하는 보상의 계산을 조금 간단하게 표현해보자.
각 약재의 보상은 각기 다른 확률분포를 따르고,
빨간 약을 선택하는 확률은 베르누이(이항)분포를 따른다고 할 때,
빨간 약을 선택할 때 받을 수 있는 평균적인 보상은,실패했을 때의 확률(0.5)에 -11,
그리고 성공했을 때의 확률(0.5)에 9를 곱하면 된다.
'데이터사이언스 > 강화학습' 카테고리의 다른 글
| 강화학습 - (6) 보상 (2) | 2020.09.07 |
|---|---|
| 강화학습 - (5) 마르코프 결정과정 (0) | 2020.09.06 |
| 강화학습 - (4) UCB (0) | 2020.08.27 |
| 강화학습 - (3) 탐색과 활용 (0) | 2020.08.24 |
| 강화학습 - (2) 행동가치함수 (2) | 2020.08.24 |