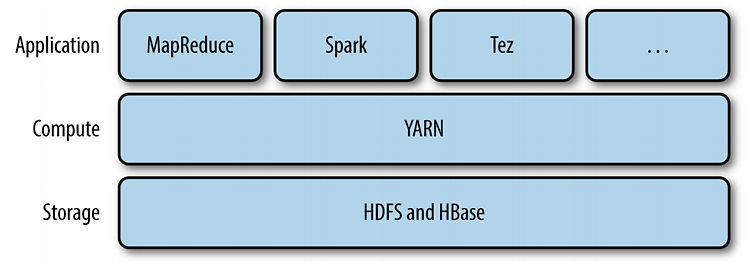
Yarn 얀의 이름은 Yet Another Resource Negotiator의 약자이다. 얀은 한마디로 하둡의 리소스를 관리하고 관장하는 시스템이다. 얀의 등장에 의해 하둡은 큰 아키텍쳐의 변화가 생겼다. 1.0에서는 HDFS와 MapReduce만 있는 구조였지만, 얀의 리소스 매니저가 다른 어플리케이션도 지원하면서, 여러 어플리케이션이 HDFS를 접근할 수 있게 되었다. 이 때문에 하둡 위에 Spark나 Hbase와 같은 시스템들이 올라갈 수 있는것이다. HDFS의 일이 파일을 읽고 쓰는 일이었다면, 얀의 일은 자원을 요청하고 할당하는 일이다. 하지만 이는 사용자(개발자)가 해주지 않고, 시스템이 알아서 해주는 것이다. 얀 어플리케이션은 클라이언트로부터 요청을 받으면 먼저 리소스매니저에게 전달 된다...